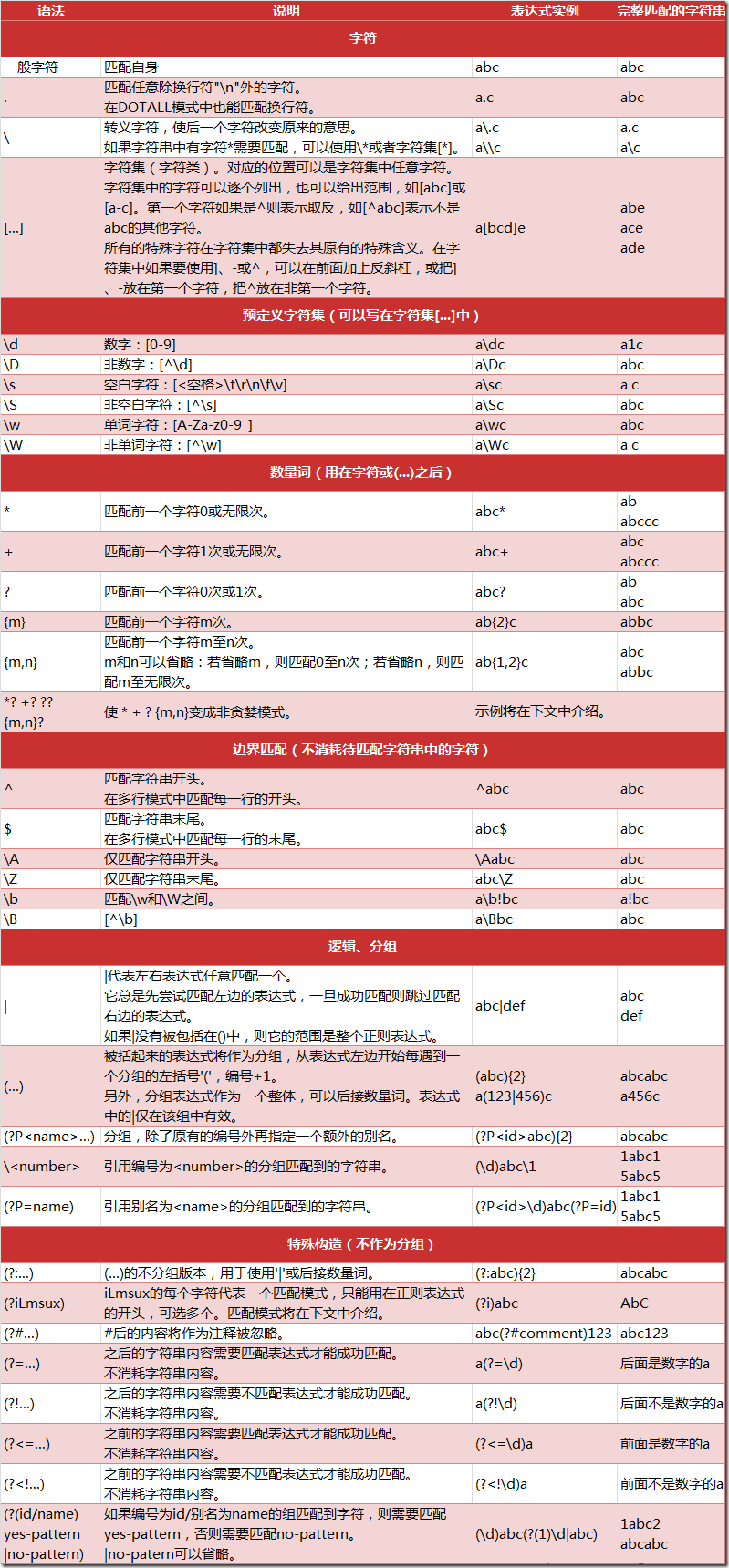
特殊符号和字符 最简单正则表达式
不使用任何特殊符号,值匹配字符串本身
正则表达式
匹配的字符串
foo
foo
Python
Python
使用择一匹配符号匹配多个正则表达式模式
正则表达式
匹配的字符串
at|home
at、home
bat|bet|bit
bat、bet、bit
例子
1 2 3 4 5 6 7 >>> import re>>> pattern = re.compile (r'bat|bit' )>>> r1 = re.match (pattern,'bat bet bit' )>>> r1<re.Match object ; span=(0 , 3 ), match ='bat' > >>> print (r1.group())bat
匹配任意单个字符
正则表达式模式
匹配的字符串
f.o
匹配在字母“f”和“o”之间的任意一个字符;例如fao、f9o、f#o等
..
任意两个字符
.end
匹配在字符串end之前的任意一个字
从字符串起始或者结尾或者单词边界匹配
正则表达式模式
匹配的字符串
^From
任何以From作为起始的字符串
/bin/tcsh$
任何以/bin/tcsh作为结尾的字符串
^Subject:his
任何由单独的字符串Subject:hi构成的字符串
the
任何包含the的字符串
\bthe
任何以the开始的字符串
\bthe\b
仅仅匹配单词the
\Bthe
任何包含但并不以the作为起始的字符串
匹配限定范围的任意字符
用[]来匹配方括号对中包含的任何字符
正则表达式模式
匹配的字符串
b[aeiu]t
bat、bet、bit、but
[cr][23][dp][o2]
一个包含四个字符的字符串,第一个字符是“c”或“r”,然后是“2”或“3”,后面是“d”或“p”,最后要么是“o”要么是“2”。例如,c2do、r3p2、r2a2、c3po等
限定范围和否定
方括号中两个符号中间用连字符(-)连接,用于指定一个字符的范围;例如,A-Z、a-z或者0-9分别用于表示大写字母、小写字母和数值数字。
另外,如果脱字符(A)紧跟在左方括号后面,这个符号就表示不匹配给定字符集中的任何一个字符。
正则表达式模式
匹配的字符串
Z.[0-9]
字母“z”后面跟着任何一个字符,然后跟着一个数字
[r-u][env-y][us]
字母“r”、“s”、“t”或者“u”后面跟着“e”、“n”、“v”、“w”、“x”或者“y”,然后跟着“u”或者“s”
[^aeiou]
一个非元音字符(练习:为什么我们说“非元音”而不是“辅音”?)
[^\t\n]
不匹配制表符或者\n
[“-a]
在一个ASCII系统中,所有字符都位于“”和“a”之间,即34-97之间
使用闭包操作符实现存在性和频数匹配
本节介绍最常用的正则表达式符号,即特殊符号*、+和?,所有这些都可以用于匹配一个、多个或者没有出现的字符串模式。
星号或者星号操作符(*)将匹配其左边的正则表达式出现零次或者多次的情况(在计算机编程语言和编译原理中,该操作称为Kleene闭包)。
加号(+)操作符将匹配一次或者多次出现的正则表达式(也叫做正闭包操作符)。
问号(?)操作符将匹配零次或者一次出现的正则表达式。
正则表达式模式
匹配的字符串
[dn]ot?
字母“d”或者“n”,后面跟着一个“o”,然后是最多一个“t”,例如,do、no、dot、not
0?[1-9]
任何数值数字,它可能前置一个“0”,例如,匹配一系列数(表示从1~9月的数值),不管是一个还是两个数字
[0-9]{15,16}
匹配15或者16个数字(例如信用卡号码)
</?[^>]+>
匹配全部有效的(和无效的)HTML标签
[KQRBNP][a-h][1-8]-[a-h][1-8]
在“长代数”标记法中,表示国际象棋合法的棋盘移动(仅移动,不包括吃子和将军)。即“K”、“Q”、“R”、“B”、“N”或“P”等字母后面加上“al”~“h8”之间的棋盘坐标。前面的坐标表示从哪里开始走棋,后面的坐标代表走到哪个位置(棋格)上
表示字符集的特殊字符
有一些特殊字符能够表示字符集。
与使用“0-9”这个范围表示十进制数相比,可以简单地使用\d表示匹配任何十进制数字。
另一个特殊字符(\w)能够用于表示全部字母数字的字符集,相当于[A-Za-z0-9]的缩写形式,
\s可以用来表示空格字符。
这些特殊字符的大写版本表示不匹配;例如,\D表示任何非十进制数(与[0-9]相同),等等。
正则表达式模式
匹配的字符串
\w+-\d+
一个由字母数字组成的字符串和一串由一个连字符分隔的数字
[A-Za-z]\w*
第一个字符是字母;其余字符(如果存在)可以是字母或者数字(几乎等价于Python中的有效标识符[参见练习])
\d{3}-\d{3}-\d{4}
美国电话号码的格式,前面是区号前缀,例如800-555-1212
\w+@\w+.com
以xxx@YYY.com 格式表示的简单电子邮件地址
使用圆括号指定分组
顾名思义,就是对正则表达式中的部分内容用()圈起来,然后再用运用正则表达式方法。对应 re 模块函数 group() 和 groups()。
正则表达式模式
匹配的字符串
\d+(\.\d*)?
表示简单浮点数的字符串;也就是说,任何十进制数字,后面可以接一个小数点和零个或者多个十进制数字,例如“0.004”、“2”、“75.”等
(Mr?s?\.)?[A-Z][a-z]*[A-Za-z-]+
名字和姓氏,以及对名字的限制(如果有,首字母必须大写,后续字母小写),全名前可以有可选的“Mr.”、“Mrs.”、“Ms.”或者“M.”作为称谓,以及灵活可选的姓氏,可以有多个单词、横线以及大写字母
扩展表示法
正则表达式模式
匹配的字符串
(?:\w+L.)*
以句点作为结尾的字符串,例如“google.”、“twitter.”、“facebook.”,但是这些配不会保存下来供后续的使用和数据检索
(?#comment)
此处并不做匹配,只是作为注释
(?=.com)
如果一个字符串后面跟着“.com”才做匹配操作,并不使用任何目标字符串
(?!.net)
如果一个字符串后面不是跟着“.net”才做匹配操作
(?<=800-)
如果字符串之前为“800-”才做匹配,假定为电话号码,同样,并不使用任何输入字符串
(?<!192\.168.)
如果一个字符串之前不是“192.168.”才做匹配操作,假定用于过滤掉一组C类IP地址
(?(1)y|x)
如果一个匹配组1(1)存在,就与y匹配;否则,就与x匹配
flag 参数flag是匹配模式,取值可以使用按位或运算符’|’表示同时生效,比如re.I | re.M。
re.I(全拼:IGNORECASE): 忽略大小写(括号内是完整写法,下同)
re.M(全拼:MULTILINE): 多行模式,改变’^’和’$’的行为(参见上图)
re.S(全拼:DOTALL): 点任意匹配模式,改变’.’的行为
re.L(全拼:LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
re.U(全拼:UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
re.X(全拼:VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
正则表达式和 Python 语言 match()方法从字符串开头进行匹配
match()函数试图从字符串的起始部分 对模式进行匹配。如果匹配成功,就返回一个匹配对象;如果匹配失败,就返回None,匹配对象的 group() 方法能够用于显示那个成功的匹配。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 >>> re.match ('foo' ,'foo' ).group()'foo' >>> re.match ('fo.' ,'foo' ).group()'foo' >>> re.match ('fo.' ,'food on the table' ).group()'foo' >>> re.match ('fo.' ,'ffood on the table' ).group()Traceback (most recent call last): File "<stdin>" , line 1 , in <module> AttributeError: 'NoneType' object has no attribute 'group' >>> re.match ('.fo.' ,'ffood on the table' ).group()'ffoo' >>> re.match ('\w*fo.' ,'ffood on the table' ).group()'ffoo' >>> re.match ('\w*d.' ,'ffood on the table' ).group()'ffood ' >>> re.match ('\w*d' ,'ffood on the table' ).group()'ffood' >>> re.match ('\w* on' ,'ffood on the table' ).group()'ffood on'
match() 只匹配以模式字符为起始的字符串,限制比较大。
search()在字符串中查找模式匹配
search() 的工作方式与match() 完全一致,不同之处在于search() 会用它的字符串参数,在任意位置 对给定正则表达式模式搜索第一次出现 的匹配情况。如果搜索到成功的匹配,就会返回一个匹配对象;否则,返回None。
1 2 3 4 5 6 7 8 9 10 >>> re.match ('on' ,'ffood on the table' ).group() Traceback (most recent call last): File "<stdin>" , line 1 , in <module> AttributeError: 'NoneType' object has no attribute 'group' >>> re.search('on' ,'ffood on the table' ).group() 'on' >>> re.search('on t' ,'ffood on the table' ).group()'on t' >>> re.search('on t..' ,'ffood on the table' ).group()'on the'
匹配多个字符串
使用择一匹配(|)符号
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 >>> bt = 'bat|bet|bit' >>> m = re.match (bt,'bat' ) >>> if m is not None :m.group()... 'bat' >>> m = re.match (bt,'bwt' ) >>> if m is not None :m.group()... >>> m = re.match (bt,'He bit me!' ) >>> if m is not None :m.group()... >>> m = re.search(bt,'He bit me!' ) >>> if m is not None :m.group()... 'bit'
匹配任何单个字符
用点号 . 匹配任意单个字符(包括数字)除了 \n 或者空字符串。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 >>> import re>>> anyend = '.end' >>> m = re.match (anyend,'bend' ) >>> if m is not None : m.group()... 'bend' >>> m = re.match (anyend,'end' ) >>> if m is not None : m.group()... >>> m = re.match (anyend,'\nend' ) >>> if m is not None : m.group()... >>> m = re.search(anyend,'The end.' ) >>> if m is not None : m.group()... ' end'
匹配字符串中的小数点
在正则表达式中,小数点 . 代表匹配任何单个非空非\n字符;那如何匹配一个真正的小数点呢?Python中采用\.,对小数点进行转义的方式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 >>> patt314 = '3.14' >>> pi_patt = '3\.14' >>> m = re.match (pi_patt, '3.14' )>>> if m is not None : m.group()... '3.14' >>> m = re.match (patt314, '3.14' )>>> if m is not None : m.group()... '3.14' >>> m = re.match (patt314, '3214' )>>> if m is not None : m.group()... '3214'
group() 和 groups()
group()通常用于以普通方式显示所有的匹配部分,但也能用于获取各个匹配的子组。可以使用groups())方法来获取一个包含所有匹配子字符串的元组。
1 2 3 4 5 6 7 8 9 >>> m=re.match ('(\w\w\w)-(\d\d\d)' ,'abc-123' )>>> m.group() 'abc-123' >>> m.group(1 ) 'abc' >>> m.group(2 ) '123' >>> m.groups() ('abc' , '123' )
如下为一个简单的示例,该示例展示了不同的分组排列,这将使整个事情变得更加清晰。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 >>> m=re.match ('ab' ,'ab' ) >>> m.group() 'ab' >>> m.groups() () >>> m=re.match ('(ab)' ,'ab' ) >>> m.group() 'ab' >>> m.group(1 ) 'ab' >>> m.groups() ('ab' ,) >>> m=re.match ('(a)(b)' ,'ab' ) >>> m.group() 'ab' >>> m.group(1 ) 'a' >>> m.group(2 ) 'b' >>> m.groups() ('a' , 'b' ) >>> m=re.match ('(a(b))' ,'ab' ) >>> m.group() 'ab' >>> m.group(1 ) 'ab' >>> m.group(2 ) 'b' >>> m.groups() ('ab' , 'b' )
匹配字符串的起始和结尾以及单词边界 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 >>> import re>>> m=re.search('^The' ,'The end.' ) >>> if m is not None : m.group()... 'The' >>> m=re.search(r'dog$' ,'bitethe dog' ) >>> if m is not None : m.group()... 'dog' >>> m=re.search('^The' ,'end. The' ) >>> if m is not None : m.group()... >>> m=re.search(r'\bthe' ,'bite the dog' ) >>> if m is not None : m.group()... 'the' >>> m=re.search(r'\bthe' ,'bitethe dog' ) >>> if m is not None : m.group()... >>> m=re.search(r'\Bthe' ,'bitethe dog' ) >>> if m is not None : m.group()... 'the'
使用findall()和finditer()查找每一次出现的位置
findall()查询字符串中某个正则表达式模式全部的非重复出现情况。这与search()在执行字符串搜索时类似,但与match()和search()的不同之处在于,findall()总是返回一个列表 。如果findall()没有找到匹配的部分,就返回一个空列表,但如果匹配成功,列表将包含所有成功的匹配部分(从左向右按出现顺序排列)。
1 2 3 4 5 6 >>> re.findall('car' ,'car' )['car' ] >>> re.findall('car' ,'scary' )['car' ] >>> re.findall('car' ,'scary the barcardi to the car' )['car' , 'car' , 'car' ]
附录 Python中正则表达式的一些匹配规则(CSDN)
Python中正则表达式的一些匹配规则(文字)
语法
解释
表达式
成功匹配对象
一般字符
匹配自身相对应的字符
abc
abc
|
表示左右表达式任意满足一种即可
abc|cba
abc或cba
.
匹配除换行符(\n)以外的任意单个 字符
a.c
abc、azc
\
转义字符,可以改变原字符的意思
a.c
a.c
\d
匹配任意1位数字:0~9
\dabc
1abc
\D
匹配数字以外的字符
\Dabc
aabc
\w
表示全部字母数字的字符集,相当于[A-Za-z0-9]
\w\w\w
oX2
\W
匹配非单词字符
a\Wc
a c
\s
表示空格字符(\t,\n,\r,\f,\v)
a\sc
a c
\S
匹配非空格字符
\S\Sc
1bc
[]
字符集,对应位置上可以是字符集里的任意字符
a[def]c
aec
[^]
对字符集当中的内容进行取反
a[^def]c
a2c
[a-z]
指定一个范围字符集
a[A-Z]c
aBc
*
匹配前面的字符或者子表达式0次或多次
a*b
aaab或b
+
匹配前一个字符或子表达式一次或多次
a+b
aaab或ab
?
匹配前一个字符或子表达式0次或1次重复
a?b
ab或b
{m}
匹配前一个字符或子表达式
a{3}b
aaab
{m,n}
匹配前一个字符或子表达式至少m次至n次(如省略m,则匹配0~n次;如省略n,则匹配m至无限次。)
a{3,5}b和a{3,}
aaaab和aaaaaab
^
匹配字符串的开始,多行内容时匹配每一行的开始
^abc
abc
$
匹配字符串的结尾,多行内容时匹配每一行的结尾
abc&
abc
\A
匹配字符串开始位置,忽略多行模式
\Aabc
abc
\Z
匹配字符串结束位置,忽略多行模式
abc\Z
abc
\b
匹配一个单词的边界,模式必须位于单词的起始部分,不管单词位于行首或者位于字符串中间
hello \bworld
hello world
\B
匹配出现在一个单词中间的模式,即与 \b 相反
he\Bllo
hello
(…)
将被括起来的表达式作为一个分组,可以使用索引单独取出
(abc)d
abcd
(?P<name>…)
为该分组起一个名字,可以用索引或名字去除该分组
(?P<id>abc)d
abcd
\number
引用索引为number中的内容
(abc)d\1
abcdabc
(?P=name)
引用该name分组中的内容
(?P<id>abc)d(?P=id)
abcdabc
(?:…)
分组的不捕获模式,计算索引时会跳过这个分组
(?:a)b(c)d\1
abcdc
(?iLmsux)
分组中可以设置模式,iLmsux之中的每个字符代表一个模式,单独介绍
(?i)abc
Abc
(?#…)
注释,#后面的内容会被忽略
ab(?#注释)123
ab123
(?=…)
顺序肯定环视,表示所在位置右侧能够匹配括号内正则
a(?=\d)
a1最后的结果得到a
(?!…)
顺序否定环视,表示所在位置右侧不能匹配括号内正则
a(?!\w)
a c最后的结果得到a
(?<=…)
逆序肯定环视,表示所在位置左侧能够匹配括号内正则
1(?<=\w)a
1a
(?<!…)
逆序否定环视,表示所在位置左侧不能匹配括号内正则
1 (?<!\w)a
1 a
(?(id/name)yes|no)
如果前面的索引为id或者名字为name的分组匹配成功则匹配yes区域的表达式,否则匹配no区域的表达式,no可以省略
(\d)(?(1)\d|a)
32